AI for Biodiversity ↔︎ Biodiversity for AI
AI → Biodiversity
Earth faces unprecedented biodiversity crisis
<10% of ~20M species scientifically named
Explosion of multimodal data:
🧬 DNA barcoding
📸 Imaging
🎤 Bioacoustics
Shift from lab to “in-the-wild”
Foundation models across modalities
Biodiversity → AI
Complex, hierarchical data structures
Long-tailed species distribution
Fine-grained recognition challenges
Out-of-distribution performance
Continual learning requirements
Let me start with why I think AI and biodiversity is such an important and interesting place to study for someone with my background. I come from deep learning and neural networks - I’ve done extensive work on vision and time series models, and more recently I’ve been getting into language models, particularly DNA sequence models.
Earth’s biodiversity faces an unprecedented crisis , with scientists warning of a sixth mass extinction. This decline threatens ecosystem health and human well-being, yet our ability to intervene is limited by vast knowledge gaps. Less than 10% of an estimated 20 million multicellular species have been scientifically named. What’s particularly exciting is that there’s an explosion of multimodal data being generated - DNA barcoding, imaging, and bioacoustics - shifting from lab-based to “in-the-wild” observations. We’re seeing the development of foundation models across the vision modality, the DNA modality, and the language modality, and it’s at this intersection where my team has been working.
But here’s what makes this research area especially compelling : while AI promises to mitigate the biodiversity crisis, biodiversity science reciprocally offers a sandbox for tackling fundamental AI and machine learning problems at scale . The complex, hierarchical nature of biodiversity data presents challenges for core ML research. The long-tailed distribution of species abundance provides a real-world context for learning from imbalanced datasets. Taxonomic classification challenges our ability to distinguish subtle differences in images or acoustic data. Ecological systems’ dynamic nature demands innovations in out-of-distribution performance and continual learning. This bidirectional relationship means we’re not just applying AI to solve biodiversity problems - we’re advancing the fundamental science of AI itself.
5 million specimensImages + DNA barcodes + taxonomic labels Challenge: Incomplete taxonomic annotations
Many labels only to family/genus level
Expert annotation is difficult
Now let me move on to actually putting the data together for machine learning and building models for biodiversity monitoring and species discovery. I’ll talk about the development of the BIOSCAN-5M dataset and its impressive scale - we’re talking about 5 million specimens with paired images, DNA barcodes, and taxonomic labels .
One important challenge I want to highlight is that taxonomic labels don’t always go to the final level of taxonomic precision , which are the species. Sometimes, because it’s such a difficult problem to annotate this data, even experts can only classify to family or genus level for much of the dataset. Annotator uncertainty is a fundamental challenge in our field.
Gradual Disempowerment: A Different Kind of Risk
“We might all find ourselves struggling to hold on to money, influence, even relevance. This new world could be more friendly and humane in many ways, while it lasts… But humans would be a drag on growth.”
— David Duvenaud , The Guardian , “Better at everything: how AI could make human beings irrelevant”
I want to bring your attention to another recent article on the question of gradual disempowerment . David Duvenaud from U of T and his collaborators point out that while a lot of attention has been placed on apocalyptic AI scenarios - humans suddenly losing power to AI systems - there could be much less sinister but equally disruptive scenarios.
We could gradually lose our ability to compete with AI and effectively become irrelevant. This connects directly to what the METR study shows us - as AI systems become capable of handling longer and more complex tasks, they’re moving into territory that was previously the exclusive domain of human professionals. It will be hard to justify spending twice as much for human work that’s only half as good.
Skills Being Automated
🔍 Web Search & Literature Review
LLM-powered search replacing Google
Synthesis in seconds vs hours
Multiple sources browsed automatically
💻 Software Development
GitHub Copilot, Cursor, Claude Code
AI agent: 660 commits, top contributor
From autocomplete to autonomous development
💡 Data Analysis & Ideation
Creative tasks being automated
Research ideation affected
No longer “human-only” territory
When you think about our jobs as bioinformaticians, several skills that are part of our general skill set are quickly being automated, if they haven’t been automated already. Let me call out the main areas :
LLM-powered search tools are rapidly replacing traditional Google searches, delivering superior results by browsing multiple sources and synthesizing information in seconds rather than hours.
[TRIGGER FRAGMENT] Many of you know about the rapid advancement of AI coding tools like GitHub Copilot, Cursor, and agentic platforms like Claude Code.
[TRIGGER FRAGMENT] Even tasks that were firmly in the realm of creative thinking, including data analysis and proposing novel research ideas , are being affected. We’re not being spared from automation in any area.
Agentic Coding: The Paradigm Shift
Autocomplete (GitHub Copilot) → seconds of autonomyPair Programming (Cursor) → minutes of autonomyAgentic Development (Claude Code) → hours of autonomy
And the result?
“Catnip for programmers”
Now let me move on to software development. As students in the bioinformatics or biotechnology programs, based on my observations at last year’s posters, I know almost all of you are writing software . Many of you are probably getting exposure to agentic software development.
What we’re seeing is a fundamental shift in how we write code. Armin Ronacher, the creator of the Python Flask framework, describes this as moving away from AI simply auto-completing your thoughts to something much more powerful - real-time collaboration between human and AI. You’re working together with an agent that can break down complex tasks, execute them step by step, and work autonomously for extended periods while you oversee and guide the process.
A friend called this “catnip for programmers ,” and Ronacher says it really feels like that - incredibly energizing and addictive in a way that traditional coding tools aren’t.
The Future: Nerd Managers
Workflow Evolution
Open GitHub issue
Agent works autonomously
Returns with PR
Review and merge
VIDEO
Future Vision
“Developers will be empowered to keep work queues full in large fleets of coding agents” - Steve Yegge
There’s an interesting recent interview between Jack Clark from Anthropic and Tyler Cowen that I recommend, where Jack Clark describes a future of “nerd managers ” - people who are effectively managers of AI systems, babysitting agents that are spinning away and responding to them when they come to you, almost like managing a team of human interns. Ethan Mollick has remarked that organizations will need to update their org-charts to reflect human and machine collaboration.
In this video from All Hands AI , Graham Neubig, who is also a professor at CMU demos his own development workflow , which is largely GitHub-based rather than in an IDE. He’s effectively opening issues, describing bugs or features he needs help with in plain language. The agent takes that over and works away while he goes and opens up another issue for another agent. He can interact with an agent if it gets stuck, but the idea is that the agent returns with a pull request in GitHub with its completed work, which he can then review and merge. He’s typically overseeing 3-5 agents at a time .
What skills are needed for agentic development?
Graham Neubig from All Hands AI suggests these key skills:
🏗️🥧 Strong architecture skills and taste
💬 Communication
📖 Code reading
🔄 Multitasking
I like that Neubig is documenting his workflow . But I like even more his comments about what skills are really needed for agentic development . He talks about strong architecture skills and taste, communication, code reading, and multitasking. Of these skills, taste is really special, but I think it’s the most nebulous .
Taste is essentially the ability to discriminate between good and bad outputs , to recognize quality and appropriateness in AI-generated content. It’s a fundamentally human skill that becomes crucial when you’re managing AI systems rather than doing all the work yourself.
Taste and RLHF
Model copies full human output distribution . That includes occasional mistakes and mediocre phrasing. Ceiling ≈ human average.
Model samples its own answers and a human simply picks the better one . Humans don’t have to create perfection, only recognise it.
Humans are far stronger critics than creators . Preference-grading lets them steer the model away from the left tail (bad answers) and pull the whole distribution rightward.
Training signal = “produce exactly what a human would have written.”
Training signal = “move towards whichever candidate the human preferred.”
Over many iterations the reward model keeps nudging the policy towards the best-judged answers, eventually surpassing the median human.
And there’s a really cool connection between taste and reinforcement learning with human feedback (RLHF) training , the “secret sauce” of LLMs.
Thomas Scialom, who led Llama2 and Llama3 post-training at Meta, provides compelling insight into why this discrimination ability is so powerful .
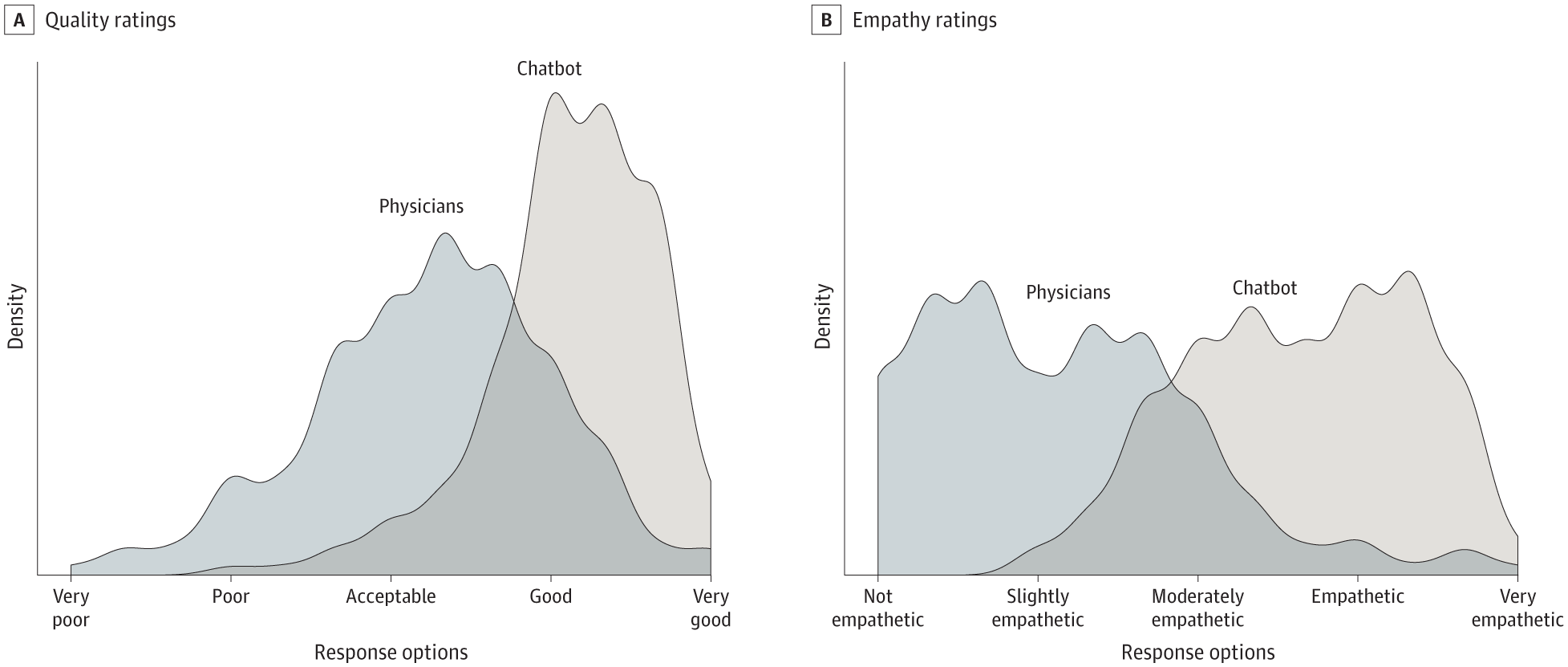
How can it be that chatbots don’t just match the physician distribution on quality or empathy, they actually go beyond it ?
This is not due to supervised instruction tuning , which trains the model to match the humans’ distribution. It’s due to RLHF.
RLHF works because people are better at saying which answer is better than at writing the perfect answer themselves. By constantly rewarding the model’s best candidate and punishing the worst, you squeeze out the bad tail and push the whole distribution past typical human performance.
Developing Taste in Graduate School
Practice Deliberate Comparison
Generate multiple AI outputs for the same task and practice choosing which is better, articulating your reasoning
Develop familiarity with different frontier models and learn what each excels at
Platform selection itself is an exercise in taste
Engage in Structured Peer Collaboration
Seek out reviewing opportunities for conferences and journals to practice evaluating others’ work
Participate in code review with lab mates or open source projects to develop technical judgment
Don’t work in isolation - co-author papers with both senior and junior students, getting comfortable with giving and receiving feedback
Seek Active Mentorship
Ask experienced researchers to walk through their decision-making when they assess quality
Submit your own quality judgments to mentors for validation and refinement
No “Taste 101” course - learn by doing
Taste isn’t traditionally taught directly - it’s gained implicitly. There’s no course in developing your taste. I notice this with students coming into master’s or PhD programs. Often when they’re collecting references and producing citations in early paper drafts or doing literature reviews, they’re not really discriminating among the quality of publication venues - where those works are published, or the authors or groups behind those papers.
So how are you supposed to develop this skill? Here are some concrete approaches :
Practice deliberate comparison and platform selection . When working with AI tools, generate multiple outputs for the same task and practice choosing which is better, articulating your reasoning. Develop familiarity with different AI platforms - Claude, ChatGPT, Gemini - and learn what each excels at. This platform selection itself is an exercise in developing taste.
Engage in structured peer collaboration . Seek out reviewing opportunities for conferences and journals. If that’s not possible you can paper review sessions where everyone reads the same paper, writes individual reviews, then discusses differences in judgment. Participate in code review with lab mates or in open source projects. Don’t work in isolation - co-author papers with both senior and junior students, getting comfortable with giving and receiving feedback.
And if you have the opportunity to work with experienced researchers directly , ask them to walk through their quality assessments with you. Have them give you feedback on your own quality judgments.
The AI Execution Gap
Study details:
Prior studies found settings where LLM-generated research ideas were judged as more novel than human-expert ideas
This study: 43 researchers, 100+ hours each
Randomly assigned to execute AI-generated or human-expert ideas
And there’s even more good news . Recent research from Stanford reveals something called the AI execution gap, which shows where humans maintain their edge. While many studies have found that LLM-generated research ideas seem more novel than human ideas at first glance, this study went further - they actually had experts implement the ideas.
Here’s what they did: 43 NLP researchers each spent over 100 hours implementing either AI-generated or human-expert ideas, then wrote papers documenting their results. When these papers were blindly reviewed, something interesting happened.
Although LLM-generated ideas may seem more novel at the ideation stage, they suffer a larger drop in novelty, excitement, effectiveness, and overall score after execution , effectively closing—and in some metrics reversing—the gap between AI and human ideas.
Are Junior Developers in Trouble?
MYTH: Junior developers are doomed
REALITY: You’re best positioned to succeed
✓ Quick to adopt AI-driven workflows✓ Treat AI tools as on-the-job training✓ Unburdened by legacy tooling
“Junior devs are vibing. They get it. The world is changing, and you have to adapt. So they adapt!”
“It’s not AI’s job to prove it’s better than you. It’s your job to get better using AI.” - Steve Yegge, “Revenge of the Junior Developer”
There’s been a lot of negative talk about career prospects for young professionals entering fields adjacent to bioinformatics and biotechnology. Are you all doomed? Is AI going to eliminate entry-level positions before you even get started?
I think this narrative is not only wrong, but backwards . Let me explain why I believe you’re actually in the best position to thrive in this new landscape.
Here I lean on an essay by Steve Yegge from Sourcegraph called “revenge of the junior developer ”. His key argument is that it’s actually the junior developers who are positioned well for success in the AI era because they’re adaptable, dynamic, and embracing these new agentic platforms.
It’s actually the legacy developers who tend to be comfortable in their careers and tooling that face the most disruption by AI systems.
Two Simple Rules
“AI can be used to avoid learning, and AI can be used to assist learning”
“It’s ok to ask AI to do things you already know how to do,
Summing this all up, my colleague Andrew Hamilton-Wright , who many of you know as the co-coordinator of the MBINF research project course, said to me recently, very nicely: “AI can be used to avoid learning, and AI can be used to assist learning.”
This distinction is so important that OpenAI just released “study mode” in ChatGPT, specifically designed to help students work through problems step by step instead of just getting answers. Rather than providing solutions outright, it uses Socratic questioning and guided prompts to help you build understanding. As one student put it during testing, it’s like having “a live, 24/7, all-knowing office hours.”
How do you use AI to assist with learning rather than avoid it? Another eloquent way of capturing this was articulated by one of my postdocs, Scott Lowe : “Just don’t ask AI to do things that you don’t understand.”
Because if you get AI to do something and you don’t have any clue how it was done, you’ve completely avoided a learning opportunity .